[논문리뷰]Training language models to follow instructionswith human feedback
2022.03.04. openAI.
LLM + RLHF의 아이디어인가보다.
0. Abstract
- LLM의 크기를 늘여도 사람의 의도를 이해하는데 한계를 보인다. 거짓말, 해로운 말 등을 한다. (not aligned with user)
- Human Feedback으로 유저와 align하게끔 finetuning 하는 법을 제시한다.
1. OpenAI API로 우리가 기대하는 모델 반응과 레이블을 작성
2. GPT-3 fine tune
3. 결과(들)을 ranking, human feedback으로 더욱 fine tune
4. Instruct GPT 완성.
- 1.3B Instruct GPT > 175B GPT-3, 진실성 증가, 해로움 감소, 공개 NLP 데이터셋에서도 좋은 성능
- 그러나 실수도 가끔씩 한다.
1. Introduction
- LLM이 NLP를 잘 수행하지만 거짓말, 편견, 해로운 말, 유저 의도 무시 등이 아직 숙제로 남아있다.
- 이런 이유는 여태까지 많은 LM들은 다음 토큰을 예측하는데 집중했고, 그것이 유저의 안전하게 도와주는 것과는 거리가 멀기 때문이다. (misaligned)
- 모델은 1.helpful, 2. honest, 3. harmless 해야 한다.

1. SFT(Supervised Fine Tuning)
2. RM(Reward Model) training
3. PPO를 이용한 RL training.
- main finding으로는
1. labler는 같은 질문에 대한 instructGPT의 응답을 chatGPT-3보다 더 선호했다.
2. 더 진실했다.
3. toxicity는 25% 우세, bias는 그대로
4. performance regression을 최소화 할 수 있었다.
- PPO-ptx
5. labler에 대해서 hold-out 검증 시도 -> 성공적.
6. 다른 NLP dataset보다 우리 labler에 기반해 학습한 모델을 더 선호
7. 지시에 따르기, 요약, 코딩 질문 잘함.
8. 실수
2. Related work
- RL은 게임에서 시작되었지만, 이젠 RLHF로써 LLM에서도 사용. 우리는 그중에서도 align에 사용.
- NLP의 fine tuning
- harm의 측정.
- harm을 최소하 하기 위한 model의 행동 제어
3. Methods and experimental details
3.1 High Level Methodology
Step 1: Collect demonstration data, and train a supervised policy.
Step 2: Collect comparison data, and train a reward model.
Step 3: Optimize a policy against the reward model using PPO.
3.2 Dataset
- OpenAPI의 playground에서 유저가 이전 버전의 instructGPT를 사용한 프롬프트를 가공해서 text prompt dataset을 만들었다.
- 그 전(최초) 버전에는 labler들에게 프롬프트를 작성하라고 지시했다.
- 우리는 3개의 dataset을 사용했다.
1. SFT dataset: text prompt sample + human desired output
2. RM dataset: model output + human ranking
3. PPO dataset: text prompt sample. no human


3.3 Tasks
- 우리의 training task는 2개의 source를 가지고 있다
1. dataset of prompt written by labler
2. dataset of prompt submitted by earlier instructGPT on API.
- 대부분 영어지만 다른 언어나 코딩도 다룬다.
- 아무튼 labler에게 최선을 다해서 유저의 intent을 추측하게끔 했음. (Appendix B 참고)
3.4 Human data collection
3.5 Models
- GPT-3를 사용했고 3가지 방법을 이용해서 training 했다. (SFT, RM, PPO)
- 각종 hyper parameters...
- RM
- K = 4 ~9 까지 비교. 예컨데 5개를 비교하면 모델은 C(5,2) = 10개의 비교 데이터 축적.
-
-reward model의 loss function은 다음과 같다:

- RL
- PPO 사용.
-Baselines
- PPO까지 끝난 모델, SFT, GPT-3,
- FLAN, T0 dataset에 대해서 GPT-3(175B)과 비교 (Appendix C 참조)
3.6 Evaluation
- 얼마나 잘 aligned되었는지를 정의하고 평가해야만 했다.
- helpfulness를 정의해야 했다. 우리는 유저의 의도와 일치함을 기준삼았다.
- 프롬프트의 의도는 labler의 판단에 맡겼다.
- 진실성(honesty)도 정의/평가해야만 했다. 모델의 "믿음"과 실제 "결과물"을 비교 해야 하는데, 모델의 믿음을 알 수는 없다. 그래서 2가지 기준을 사용했다.
1. 모델이 얼마나 없는 사실을 만들어 내는지(hallucination)
2. TruthfulQA dataset
- harm은 모델의 출력이 실제 세상에서 적용 되었을 때의 유해성을 평가하려고 했지만, 너무 많은걸 예측해야 해서 관뒀다.
- 그래서 labler에게 평가 기준 부여 + Dataset(RealTocixityPrompts, CrowS-Pair)
4. Results

4.1 Results on the API distribution
- labeler가 instruct혰fmf GPT-3보다 더 선호했다.
- 훨씬 믿을만 하고 컨트롤하기 쉬웠다.

- held-out 된 labler들도 선호했다(training data를 만든 labler의 취향이 반영되지 않았다)
- 사람을 5개로 쪼개봤는데(5-fold), held out labler에게는 69.6%, training labler에게는 72.4%의 accuracy로 작은 차이가 났다.
- Public NLP dataset은 언어모델의 실사용을 반영하지 않는다.
- FLAN과 T0보다 성능이 좋았다.
- public NLP dataset은 평가하기 쉬운 항목들로 이루어져 있다. (분류, 질의응답, 번역, 요약)
- 실제의 사용은 open-ended generation과 brainstorming이 57%.

4.2 Results on the public NLP datasets
- improvements on truthfulness

- 회색: Truthfulness, 색깔: Truthfulness & informativeness
- 평가기준: TruthfulQA dataset에 대한 인간의 평가.
- Toxicity는 소량 감소, bias는 그대로
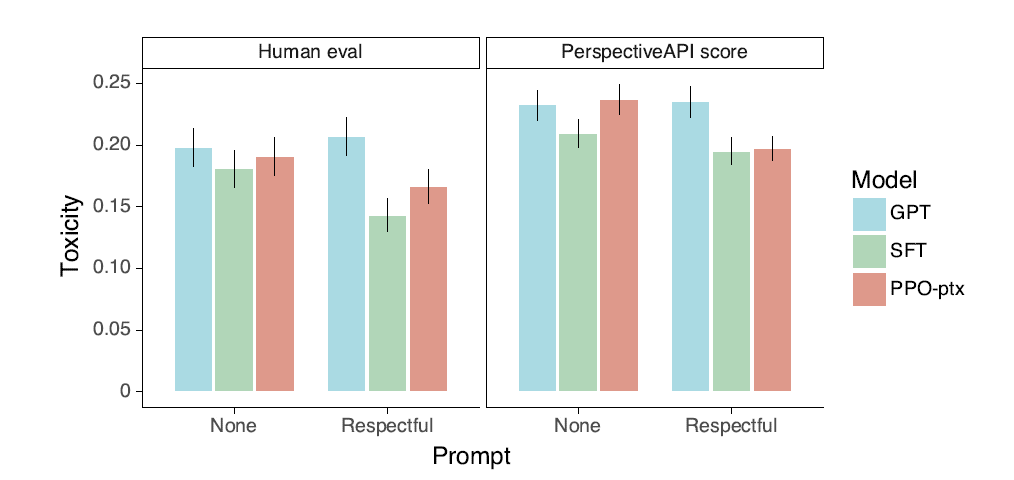
- 평가기준: RealToxicityPrompt을 주고 1. PerspectiveAPI 2. 인간 평가
( fig 39 참고)
- 안전한 출력을 요구했을 때는 더 착했지만, 유해한 프롬프트에는 유해한 출력

- RLHF의 파인튜닝을 조정함으로써 성능저하를 줄일 수 있었다.
- pretraining update를 추가하는것이 KL coefficient를 증가시키는 것보다 더 나앗다(fig 29, 33)


4.3 Qualitative results
- summarize를 더 잘한다.
- 개선점:
1. 거짓 전제의 질문에 속는다
2. overly hedge. 하나의 답이 있어도 자꾸 미미한 답까지 고려
3. 여러가지 제약이 있을 때 성능 저하
5. Discussion
5.1 implications on alignment research
- general lessons
1. model alignment cost < pretraining cost
2. 지시를 따를 때 일반화 능력이 있더라
3. low-tax alignment technique
4. real world에 쓸 수 있는 aligned model을 제시했다.
5.2 who are we align to?
- labler의 성향.
- 우리(openAI)의 성향
- openAI playground에 프롬프트를 제출한 유저의 성향
- 처음은 직원, 그 다음은 waitlist에서 골라진 유저
- 모두의 성향을 만족시키는 model을 만드는건 불가능하고, 그것은 우리의 목표가 아니다.
5.3 Limitations
- Methodology
- labler의 편향이 들어갈 수 있다...
- Models
- model 자체가 여전히 toxic한 출력을 제공할 수 있다...
5.4 Open Questions
- adversarial set-up labler를 이용할 수도 있었다. (최악의 답변을 골라서 데이터셋에 포함)
5.5 Broader Impacts
A. Additional prompt data details
- 프롬프트의 종류가 있는데, 이 분류는 langid.py 라는 경량화 분류 모델을 사용했다.

B. Additional human data collection details
C. Additional model details
- 모든 아키텍쳐는 GPT-3
C.1 Details of SFT training
- 16 epoch, 0.2 dropout, ... ...
C.2 Details of RM training
- 모든 사이즈의 PPO 모델에 대해서 6B RM model을 썼다.
- 마지막 reward model 역시 6B GPT-3의 파인 튜닝 버전을 썼다.
C.3 Details of initialization models for RLHF
- RLHF 모델도 pretrained 된 GPT-3 사용. (E.11)
D. Automatic evaluation details
D1. Toxicity and bias evaluation details
- basic, respectful, biased prompt를 작성한다.
- average entropy (??)
D2. Prompt structure and evaulation features for each eval dataset
E. Additional results
E1. Perfoamances on public NLP datasets
- 여러 nlp dataset에 대해서 bias, toxicity, truthfulness 와 여러 언어능력을 실험해봤다.
- PPO 가 그 자체로는 성능이 안좋았지만 PPO-ptx는 성능이 좋아짐을 알 수 있다.

E.2 Reward model generalization across sets of lablers
E.3 Metadata results as a function of model size
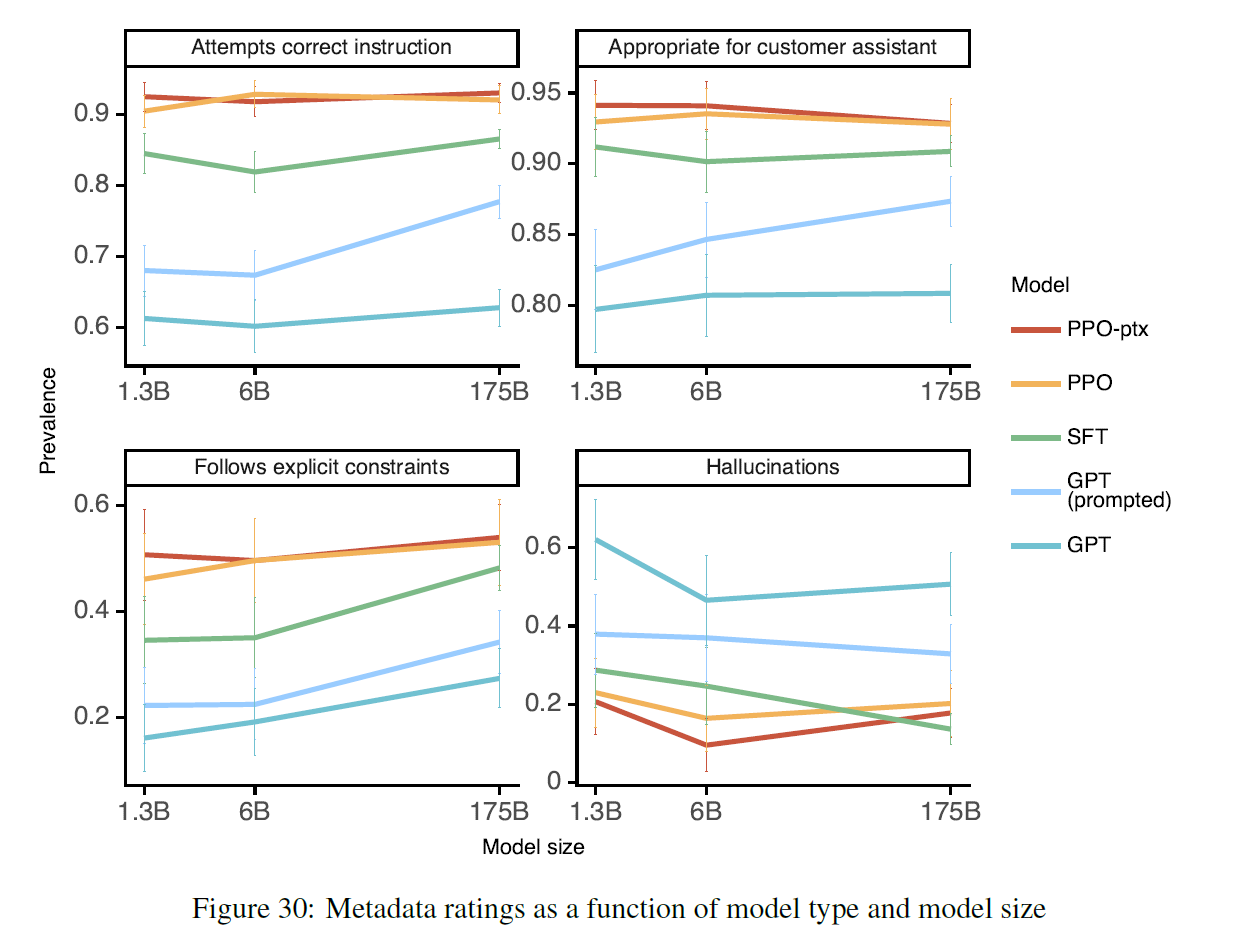
E.4 Likert scores
(Section 4.1과 비슷하다) (???)
E.5 Measuring bias
E.6 Fixing regression on public NLP datasets
E7. Optimal KL reward coefficient
- KL이 pretrained ... 계수보다는 중요하지 않지만 그래도 유의미했다.
E8. PPO init model
- pretrained data mix가 10%, 50%, 100%가 있었는데, 10%가 효과가 좋았다.
*Question
Q1: what is PPO?
Q2. what is performance regression in RLHF?
Q3. what is PPO-ptx?
Q4. held-out?
A4: hold-out 검증은 data를 train/test set으로 나누고 훈련 검증하는 방식이다.
Q5: likert scale?
A5: likert 척도는 1-5까지 동의 여부를 묻는 검사방법.
Q6: KL coefficient?